یادگیری ماشین کوانتومی (Quantum Machine Learning) پدیدهی بزرگ بعدی است
بیشتر ما نام هوش مصنوعی و محاسبات کوانتومی را شنیدهایم. اما آیا چیزی دربارهی یادگیری ماشین کوانتومی شنیدهایم؟
یادگیری ماشین کوانتومی نقطهی تلاقی محاسبات کوانتومی و هوش مصنوعی است که قرار است آینده را متحول کند.
هرکدام بهتنهایی شگفتانگیز هستند، اما وقتی با هم ترکیب شوند، غیرقابل توقف خواهند بود.
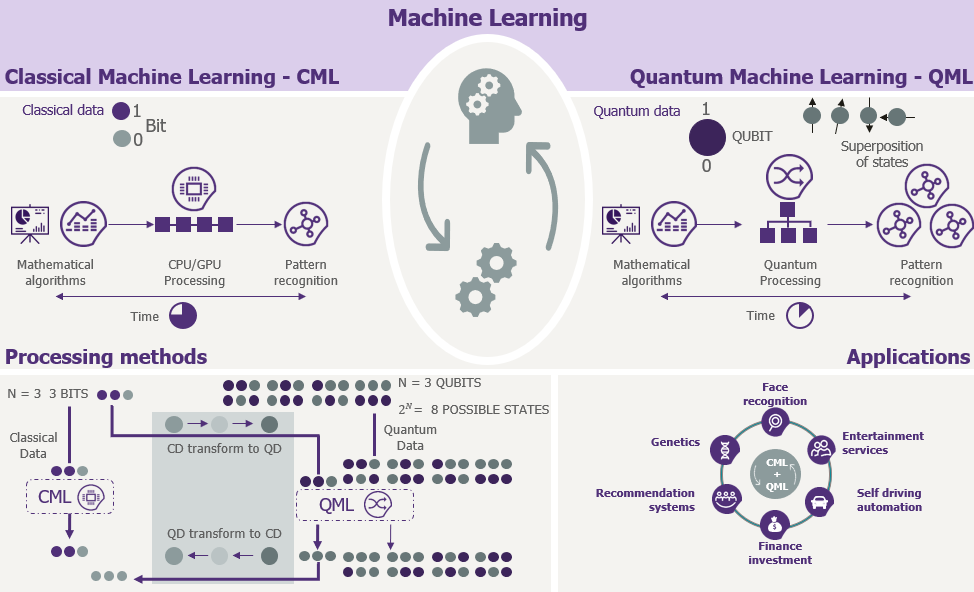
یادگیری ماشین کلاسیک
یادگیری ماشین را میتوان به سه گروه اصلی تقسیم کرد: ۱. یادگیری نظارت شده (supervised learning) که در آن از دادههای آموزشی برای پیشبینی مقدار بعدی استفاده میشود، ۲. یادگیری بدون نظارت (unsupervised learning) که بر روی دادههای بدون برچسب عمل میکند، ۳. یادگیری تقویتی (reinforcement learning) که از محیط و اشتباهات خود یاد میگیرد.
ماشینهای بردار پشتیبان (Support Vector Machines یا SVM) در دسته یادگیری نظارت شده قرار میگیرند و تمرکز ما روی این نوع یادگیری است.
الگوریتمهای یادگیری نظارت شده از مثالها یاد میگیرند. در یادگیری نظارت شده، شما متغیرهای ورودی (X) و یک متغیر خروجی (Y) دارید. هدف الگوریتم این است که یاد بگیرد چگونه تابعی را ایجاد کند که ورودی را به خروجی نگاشت کند.
Y = f(X)
هدف الگوریتم این است که تابع نگاشت را آنقدر خوب تقریب بزند که وقتی داده ورودی جدید (X) دارید، بتوانید متغیر خروجی (Y) آن داده را پیشبینی کنید.
برای مثال، الگوریتم یادگیری نظارت شده میتواند با استفاده از یک مجموعه داده آموزشی، تفاوت بین دو نوع شیء (گربه و سگ) را درک کند. الگوریتم ویژگیهای مختلف (مو، رنگ، چشم، گوش و غیره) را تحلیل میکند تا یاد بگیرد هر شیء چگونه به نظر میرسد. سپس یک داده ناشناخته معرفی میشود (مثلاً یک سگ سفید). با استفاده از آموزش قبلی خود، الگوریتم پیشبینی میکند که این داده به کدام دسته تعلق دارد.
این نوع یادگیری «یادگیری نظارت شده» نامیده میشود چون شبیه به حالتی است که یک معلم به یک دانشآموز اطلاعات میدهد. معلم ابتدا پاسخها را به دانشآموز (یا در اینجا به الگوریتم) میدهد تا یاد بگیرد. اما در نهایت، دانشآموز به اندازه کافی مفاهیم را میفهمد و قادر میشود خودش مسائل را حل کند.
ماشینهای بردار پشتیبان (Support Vector Machines)
ماشینهای بردار پشتیبان (SVM) از قویترین الگوریتمهای یادگیری نظارتشده هستند. در این مورد، ما از آنها برای دستهبندی استفاده میکنیم، اما میتوانند برای رگرسیون هم به کار روند.
ویژگی خاص آنها از تواناییشان در دستهبندی اشیاء در فضای n-بعدی ناشی میشود (n برابر است با تعداد ویژگیها). هدف آنها یافتن یک ابرصفحه (هایپرپلین) در فضای n-بعدی است که نقاط داده را بهطور واضح طبقهبندی کند.
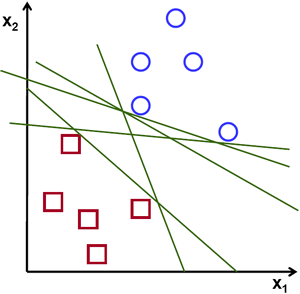
برای درک بهتر، تصور کنید یک نقاشی از یک گربه کشیدهاید و یک برچسب سگ را دقیقاً روی نقاشی گربه چسباندهاید. این یک فضای دوبعدی (n=2) است؛ و بدون توجه به تعداد خطوطی که میکشید، هیچ راهی برای جدا کردن گربه و سگ وجود ندارد. این دو بعد (مثلاً وزن و قد) برای دستهبندی اشیاء کافی نیستند.
این مشکل، مشکلی است که بسیاری از الگوریتمهای دستهبندی با آن روبرو هستند.
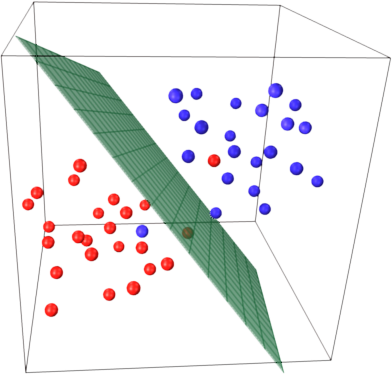
حالا بیایید با اضافه کردن بعد سوم، یعنی عمق، آن را سهبعدی کنیم (n=3). متوجه میشویم که دو شیء در این فضا همپوشانی ندارند و در عمقهای متفاوتی قرار دارند. بعد سوم (مثلاً صدای پارس سگ) به کامپیوتر کمک میکند تفاوت بین آنها را درک کند. اگر گربه و سگ را به فضای با ابعاد بالاتر منتقل کنیم، میتوانیم یک صفحه نازک (یک «صفحه») بین آنها قرار دهیم و آنها را از هم جدا کنیم.
اگرچه این خیلی ساده است، اما همین کاری است که SVMها انجام میدهند. آنها در فضای n بعدی تحلیل میکنند.
کامپیوترها تصاویر گربه یا سگ را میگیرند و پیکسلهای آنها را بر اساس ویژگیهایی مانند قد، وزن، پارس و سایر خصوصیات سازماندهی میکنند. سپس کامپیوتر از یک ترفند کرنل (kernel trick) استفاده میکند تا دادههای غیرخطی را به فضای با ابعاد بالاتر منتقل کند. نتیجه نهایی «نقشه ویژگی» (feature map) است که به ما کمک میکند بفهمیم چگونه ورودی (X) به خروجی (Y) تبدیل میشود.
اما مشکل یادگیری ماشین کلاسیک و SVMها چیست؟ چرا اصلاً نیاز به اضافه کردن کامپیوترهای کوانتومی داریم؟
وقتی دادهها به ابعاد بالاتر و بالاتر منتقل میشوند، برای کامپیوترهای کلاسیک سخت است که بتوانند با چنین محاسبات بزرگی کنار بیایند. حتی اگر کامپیوتر کلاسیک توانایی انجام آن را داشته باشد، زمان زیادی طول خواهد کشید.
به طور ساده، گاهی الگوریتمهای یادگیری ماشین کلاسیک برای کامپیوترهای کلاسیک بسیار سنگین و سخت هستند.
خوشبختانه، کامپیوترهای کوانتومی قدرت محاسباتی لازم برای انجام این الگوریتمهای سنگین را دارند. آنها از قوانین قدرتمندی مثل برهمنهی و درهمتنیدگی استفاده میکنند تا مسائل را سریعتر از کامپیوترهای کلاسیک حل کنند.
در واقع، مطالعهای توسط IBM و MIT نشان داد که ماشینهای بردار پشتیبان (SVMها) از نظر ریاضی بسیار شبیه به آنچه در داخل یک کامپیوتر کوانتومی اتفاق میافتد هستند.
یادگیری ماشین کوانتومی به دانشمندان اجازه میدهد الگوریتمهای یادگیری ماشین کلاسیک را به مدارهای کوانتومی تبدیل کنند تا بتوان آنها را به صورت کارآمد روی کامپیوتر کوانتومی اجرا کرد.
کاربردها
یادگیری ماشین کوانتومی حوزهای بسیار جدید است که پتانسیل رشد زیادی دارد. اما ما همین حالا میتوانیم شروع به پیشبینی تأثیرات آن بر آیندهمان کنیم!
در اینجا چند زمینهای که یادگیری ماشین کوانتومی (QML) آنها را متحول خواهد کرد آورده شده است:
درک نانوذرات
ایجاد مواد جدید از طریق نقشهبرداری مولکولی و اتمی
مدلسازی مولکولی برای کشف داروهای جدید و تحقیقات پزشکی
فهم ساختار عمیقتر بدن انسان
بهبود شناسایی الگو و دستهبندی
پیشبرد اکتشافات فضایی
ایجاد امنیت کامل و متصل از طریق ادغام با اینترنت اشیاء (IoT) و بلاکچین
با پیشرفتهای شگفتانگیزی که هر روز اتفاق میافتد، یادگیری ماشین کوانتومی مشکلات بیشتری را حل خواهد کرد که حتی تصورش را هم نمیکردیم.
استفاده از ماشینهای بردار پشتیبان (SVM) برای طبقهبندی بیماری پارکینسون
ما در تیم مهندسی کورپی روی ساخت یک الگوریتم یادگیری ماشین کوانتومی (QML) کار کردیم که بتواند بر اساس ویژگیهای گفتاری، تشخیص دهد آیا یک بیمار به بیماری پارکینسون مبتلا است یا خیر. ما یک شبیهسازی ۹ کیوبیتی را با استفاده از ماشین بردار پشتیبان کوانتومی روی شبیهسازهای کوانتومی IBM انجام دادیم.
چگونه الگوریتم را بسازیم: مرحله اول راهاندازی مدار کوانتومی است:
وارد کردن بستههای لازم
بارگذاری اطلاعات حساب IBM و اتصال به بهترین شبیهساز کوانتومی
تنظیم تعداد شاتها (یا تلاشهایی) که الگوریتم شما انجام میدهد
مرحله بعدی آمادهسازی دادهها است:
وارد کردن دادهها. دیتاست بیماری پارکینسون که ما استفاده کردیم را میتوانید اینجا پیدا کنید.
تقسیم دادهها به دو کلاس (حاضر و غایب)
تقسیم دادهها به مجموعههای آموزشی و آزمایشی (نسبت ۷ به ۳ برای آموزش به آزمایش ایدهآل است)
سپس باید الگوریتم یادگیری ماشین کوانتومی را بسازیم:
تعیین تعداد کیوبیتهایی که مدار خواهد داشت (تعداد کیوبیتها باید برابر با تعداد ویژگیهای دیتاست شما باشد)
راهاندازی نقشه ویژگی برای ساخت SVM
تنظیم پارامترهای لازم؛ شامل دستگاه اجرا، تعداد شاتها، و مقداردهی اولیه تولیدکننده اعداد شبهتصادفی
وارد کردن دادههای بدون برچسب برای دستهبندی
مرحله آخر اجرای الگوریتم است. روش run دقت مدار را تولید میکند. در حالی که روش predict آموزش، آزمایش و پیشبینی دادههای بدون برچسب را انجام میدهد.
نتایج نشان داده شده میتوانند با دقت 75 درصد پیشبینی کنند که آیا هر یک از ۹ بیمار به بیماری پارکینسون مبتلا هستند یا خیر. با استفاده از یک دیتاست بزرگتر و سختافزار پایدارتر، میزان دقت قطعاً افزایش خواهد یافت.
با بیماریهایی مانند پارکینسون، هر چه تشخیص زودتر باشد، درمان بهتر خواهد بود. الگوریتمهای یادگیری ماشین کوانتومی مانند این الگوریتم میتوانند پیشرفتهای چشمگیری در درمان و پیشگیری از بیماریها ایجاد کنند.
در سالهای آینده، یادگیری ماشین کوانتومی تبدیل به یک حوزه عظیم خواهد شد که توان محاسباتی آن به طور چشمگیری افزایش خواهد یافت. این فناوری قادر خواهد بود پیچیدهترین مشکلات جهان را حل کند. انقلاب هوش مصنوعی که امروز شاهد آن هستیم، زمانی که با محاسبات کوانتومی ترکیب شود، حتی بزرگتر خواهد شد.
ما بسیار هیجانزده هستیم که شاهد رشد این حوزه باشیم و ببینم چگونه به زندگی ما وارد میشود. خوشبختانه، بسیاری از آزمایشهای یادگیری ماشین کوانتومی هماکنون با فناوری کوانتومی کنونی ما امکانپذیر شدهاند. آینده همین الان اینجاست و ما آمادهاش هستیم!









دیدگاهتان را بنویسید